7 Tips for Maximizing Cloud Geo-resilience with Azure Site Recovery
With expert implementation, Azure’s disaster recovery tool boosts enterprise cloud resilience, minimizing disruption and downtime during regional outages.
With the ‘big three’ cloud hyperscalers all experiencing outages in the past year, the importance of geo-resilience is clear. Harmful effects of digital downtime can be far reaching. A recent survey suggests that annual outages cost Forbes Global 2000 companies $400B, equivalent to 9% of profits. And, as McKinsey notes, the consequences go beyond financial loss; regulators are increasingly focused on the resilience of end-to-end processes and services.
In this context, use of cloud providers’ disaster recovery services takes on added significance. Microsoft’s Azure Site Recovery is a case in point. Originally developed as a cloud-based failover mechanism for on-premises environments, it also functions as an Azure-to-Azure failover tool during regional outages. Yet the more applications you’re looking to protect, the more complex deployment becomes. What’s more, the service may not be a good fit for every application.
So, large scale deployments of Azure Site Recovery for cloud geo-resistance require careful planning and expert implementation. Read on for tips derived from Amdocs Cloud Studio’s experience handling projects for enterprise organizations in the financial services and telecoms sectors.
1. Engage Stakeholders from the Outset
It’s a good idea to include application and business stakeholders in the failover planning process. Demonstrating what’s involved helps set expectations and enables potential issues to be identified before significant time is invested.
Enabling Azure’s application-consistent snapshots is also advisable, especially for database workloads. Snapshots capture the full state of a virtual machine (VM), including in-memory data and application state. So, as well as supporting technical validation, they help stakeholders understand how applications will behave under replication. Doing this early allows any performance issues to be identified and mitigated by adjusting VM or disk configuration.
2. Prepare Your Network for Smooth Recovery and Maximum Security
Azure recommends that primary and secondary regions which are paired-up to maximize cloud resilience should be geographically distant. This way, if the primary region fails due to natural disaster, electricity blackout, or some other local incident, the secondary region is less likely to be affected.
From a network design perspective, it is best to align IP address ranges between the two regions. While IP ranges must be unique to each region, ensuring the differences are minor makes configuration easier and less error prone. It is also important that the secondary region is regularly updated along with the primary region. This can be achieved by ensuring the secondary region is part of all deployment processes.
Since components deployed for Azure Site Recovery are accessible over the public internet by default, we advocate the enablement of private or service endpoints. As the below diagram shows, this limits external users’ access to the corporate network which helps satisfy governance and compliance requirements.
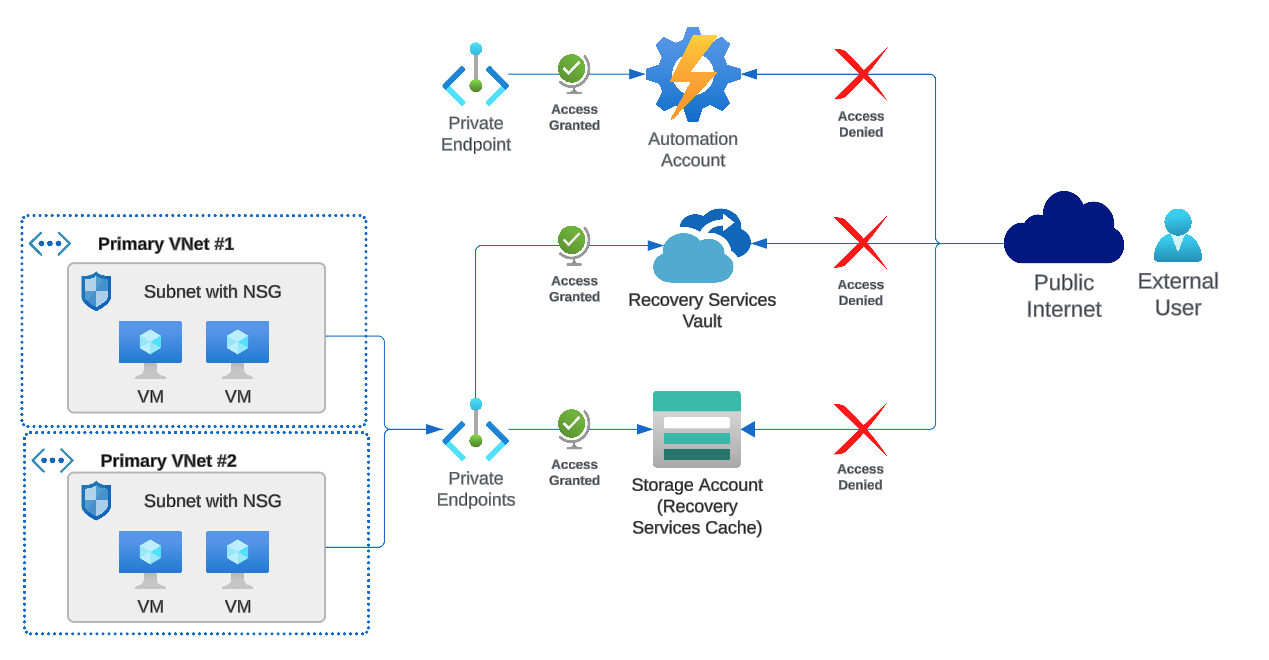
3. Configure DNS for Seamless Access
The network’s Domain Name System (DNS) requires attention too.
Azure Traffic Manager enables public DNS records to fail over from the primary to the secondary region, allowing external customers to be re-routed. However, some applications for internal use may have private DNS names that cannot be managed by this tool.
To ensure a seamless failover of private DNS names, it’s best to use Canonical Name (CNAME) records, rather than Address (A) records. This way, when a VM’s IP address is updated, the CNAME automatically follows the change without needing a manual fix.
4. Run Disaster Recovery Drills
Azure Site Recovery has a ‘Test Failover’ capability, where replicated VM data is powered on in an isolated network of the secondary region. This valuable function checks that the replicated data is usable. However, it assumes all VMs in a recovery plan are in the same Azure Virtual Network subnet, which is unlikely and is not considered best practice. Ideally, application and database servers are held in different subnets.
So, while Test Failover has a role to play, disaster recovery drills are needed for independent subnets. These should be handled directly by application and business stakeholders, following the runbook process as if they are triggering a failover in production.
5. Remediate Issues from Drill Findings, Then Repeat the Process
Any failover or failback issues detected in a disaster recovery drill must be addressed at the earliest opportunity, so they don’t impact live failover events in production. Then a re-run should be performed to check the issues have been resolved.
Even if a drill is successful, it should be repeated regularly as new problems and misconfigurations can emerge over time. For example, new disks might be added to VMs but not to replication policies, site recovery agents might become outdated, or firewall rules in the secondary region may become misaligned. It is far better to discover these issues in a dev/test scenario than in a production environment during a live event.
6. Use Modern Infrastructure Practices and Recovery Plans
When deploying Azure Site Recovery at scale, initial configuration is best managed using Infrastructure-as-Code (IaC) tools such as Terraform or Bicep. Then deployment consistency can be upheld using continuous integration / continuous delivery (CI/CD) pipelines.
As the below diagram illustrates, Amdocs Cloud Studio recommends a repository design which decouples foundational components of Azure Site Recovery from the VM replication configuration. Rather than deploying shared components, resources are deployed for individual applications. This allows multiple applications with different lifecycles to be managed independently, reducing risk by limiting the blast radius of any performance issues and simplifying configuration at the application level.
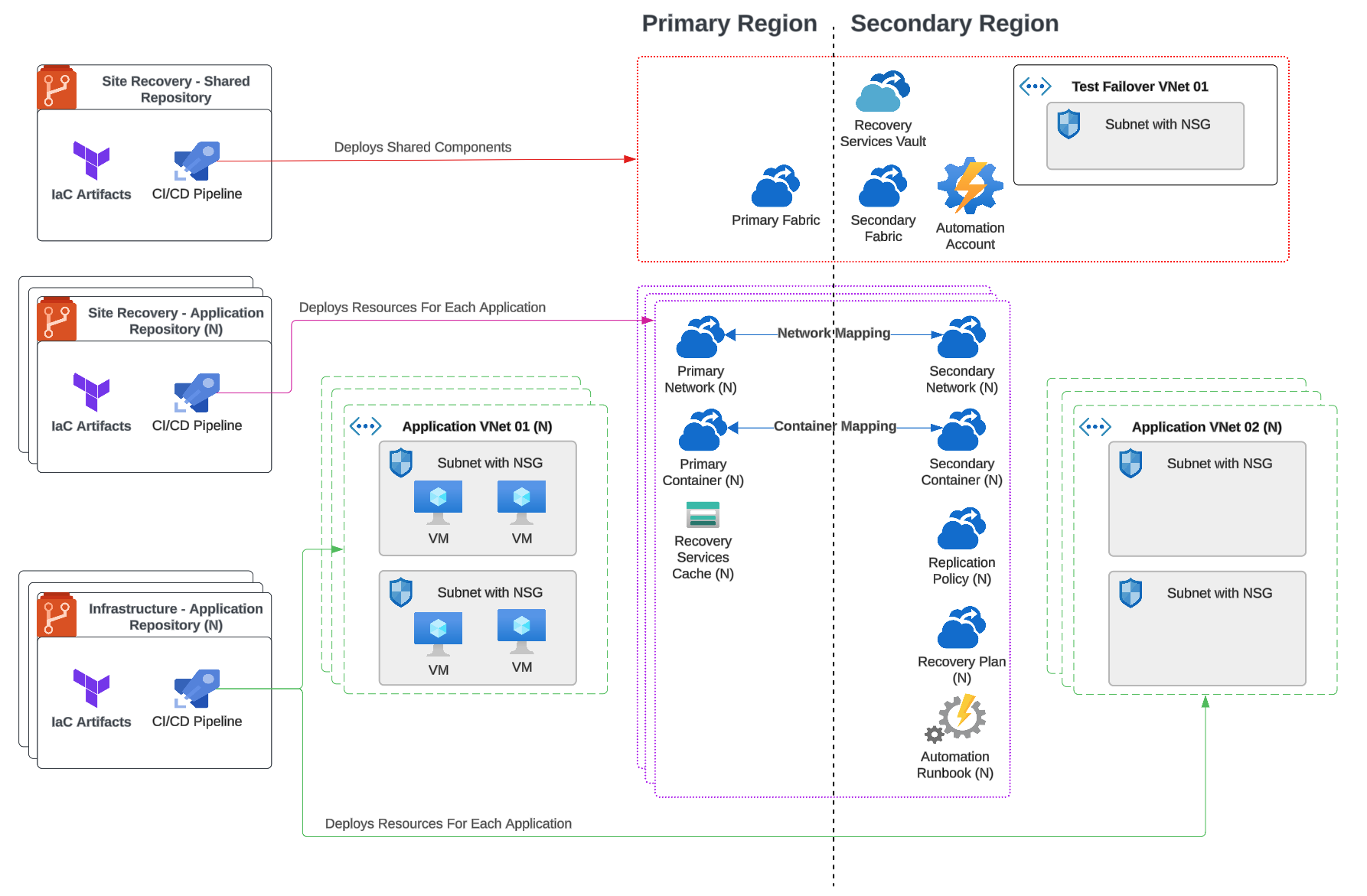
The use of recovery plans is also advisable, orchestrating the order in which VMs power on to ensure graceful start-up of applications. For example, a database server would need to be available and fully operational before the associated application server can handle customer requests. Recovery plans can also be linked to automation accounts which execute failovers for resources such as Storage Accounts not supported by Azure Site Recovery.
7. Simplify the Failover Process
While the effective implementation of Azure Site Recovery is complex, the failover process itself must be simple and accessible.
In the event of a disaster, it is possible that automated deployment (e.g. via Azure DevOps or GitHub Actions) will not be available. Therefore, it is important that the process for triggering failover can also be conducted manually in the Azure Portal, PowerShell, or the command line interface. When the primary region is available again, the IaC configuration can be re-deployed to protect the primary VM following its failback and return to the desired state.
Implementing Azure Site Recovery for a Financial Services Leader
A multinational financial services company urgently needed to modernize its manual disaster recovery process to improve operational resilience and risk management. With the existing approach, recovering the full fleet of applications took 24 hours. Disaster recovery drills involved weeks of effort from multiple teams. And outcomes were often unpredictable, impacting developer productivity and feature development.
Having previously handled the company’s data center exit and adoption of Infrastructure as a Service (IaaS) in Azure, Amdocs Cloud Studio was engaged to execute this project.
We implemented Azure Site Recovery alongside supporting components such as Traffic Manager and Azure Automation. This enabled the company to fail over to a secondary Azure region within one hour – meeting its recovery time objective (RTO) – and to achieve a recovery point objective (RPO) of just five minutes. Terraform was used to configure replication for each applicable VM, with PowerShell Automation Runbooks deployed to manage Storage Account failover.
The entire failover and failback process now takes just a few hours and involves a small subset of people. With the short RPO, it’s also possible to reduce the frequency of VM backups which delivers significant cost savings. So, as well as reducing the risk of financial loss or penalties associated with a lengthy recovery process, the approach itself delivers a good return on investment (RoI). Amdocs Cloud Studio also received positive feedback on general visibility and accessibility. The previous process was abstracted and could only be conducted by specific individuals.
Our Experts Can Help
While the geo-resilience tips outlined here center on Azure Site Recovery, the same principles apply to other cloud-based disaster recovery services. Nevertheless, since organizations and applications differ, expert judgement and bespoke implementation is essential.
Here at Amdocs Cloud Studio, we help large organizations in highly regulated sectors achieve smooth and reliable multi-region disaster recovery. If you’re looking to improve recovery times, minimize data loss, and ensure predictable outcomes, get in touch cloud@amdocs.com










