5 technical challenges in adopting data mesh architecture
Adopting data mesh can be challenging, but full of opportunity. Learn the nuances and considerations in overcoming data mesh obstacles.

Data Mesh is transforming how organizations are managing their data at scale. Despite the benefits that Data Mesh is expected to bring; it also introduces a couple of challenges. What can you do to avoid basic mistakes and make sure you get it right?
While many organizations pride themselves on striving to let data drive innovation, as their businesses grow, they discover that issues with that data inevitably begin to emerge...
- Organizational silos and lack of data sharing
- No shared understanding of what data means outside the context of its business domain
- Incompatible technologies prevent the ability to extract actionable insights
- Data is increasingly difficult to push through ETL pipelines
- Growing demands for ad hoc queries and shadow data analytics
The best solution for these problems may be an architecture that emphasizes democratization of data at the business domain level while accommodating different technologies and data analytic approaches. Since available budgets may have already been used up in previous experiments with expensive data technologies, the new solution will need to start small, prove its worth and scale as the company grows.
A data mesh architecture may be your team’s last best hope for solving your data problems. A data mesh can start small and grow as needed, providing a budget-friendly option for proving value and then growing to meet your company’s needs. Let’s explain how it works.
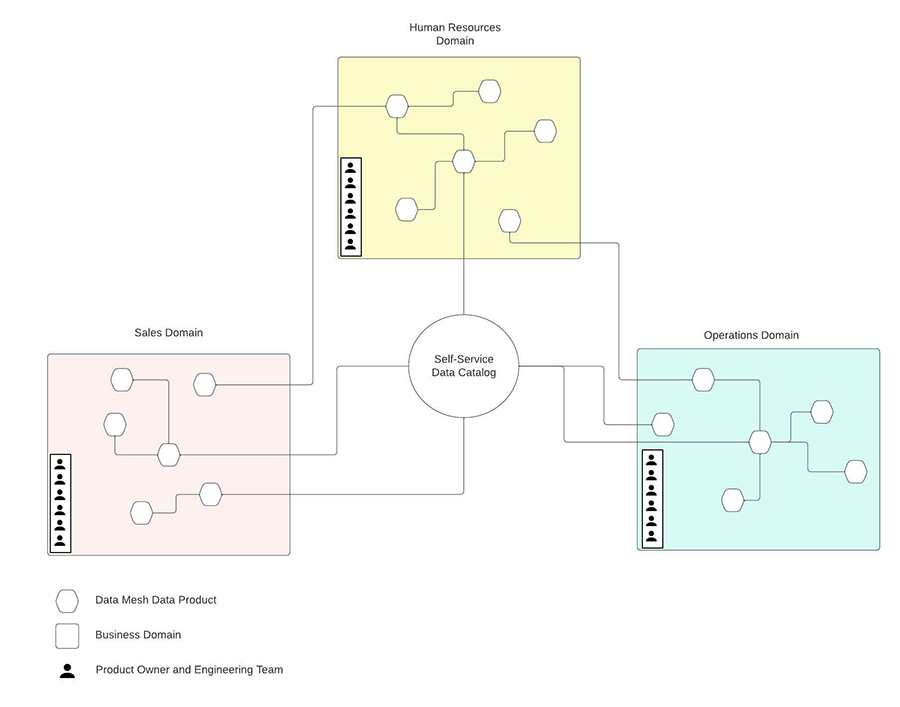
A data mesh is a distributed approach to data management that views different datasets as domain-oriented “data products”. Each set of domain data products is managed by product owners and engineers who have the best knowledge of the domain. The idea, is to employ a distributed level of data ownership and responsibility sometimes lacking in centralized, monolithic architectures like data lakes. In many ways, it’s similar to the microservice architectures commonly used throughout the industry. And because each domain implements its own data products and is responsible for its own pipelines, it avoids the tight coupling of ingestion, storage, transformation and consumption of data typical in traditional data architectures like data lakes.
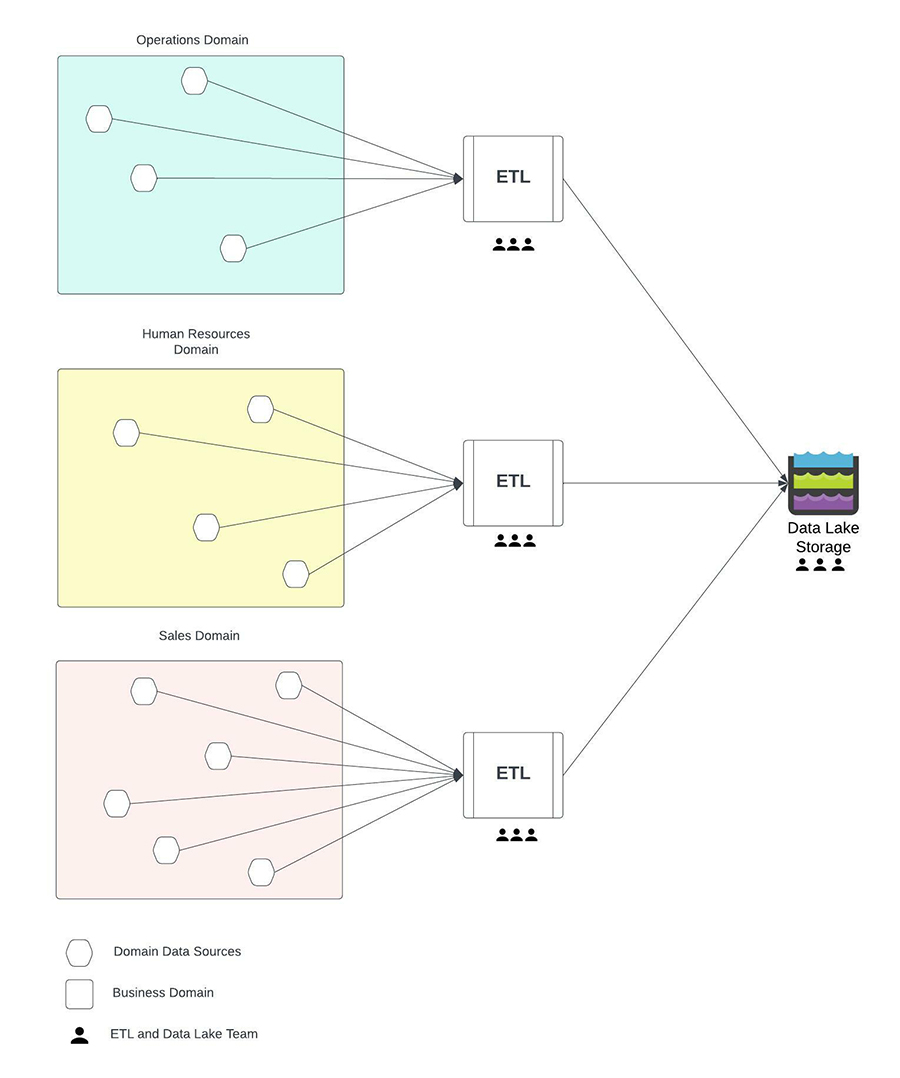
Building a success data mesh architecture requires organizations to address many technical and operational hurdles. Let’s delve into the technical challenges and how they can be overcome.
#1: Failure to follow DATSIS principles
The success of your data mesh is contingent on it being discoverable, addressable, trustworthy, self-describing, interoperable and secure (DATSIS):
- Discoverable: enable consumers to research and identify data products produced by different domains – typically via a centralized tool like a data catalog
- Addressable: like microservices, data products must be accessible via a unique address and standard protocol (REST, AMQP, possibly SQL)
- Trustworthy: domain owners must provide high-quality data products that are useful and accurate
- Self-describing: data product metadata must provide enough information to ensure consumers don’t need to query domain experts
- Interoperable: data products must be consumable by other data products
- Secure: access to each data product must be automatically regulated through in-built access policies and security standards
#2: Failure to invest in automated testing
Because a data mesh is a decentralized collection of data, its crucial to ensure consistent quality across data products owned by different teams who may not even be aware of one another. Following these principles helps:
- Every domain team must be responsible for the quality of their own data. The type of testing will depend on the nature of that data and be decided by each team.
- Take advantage of the fact the data mesh is read-only. This means that not only mock data can be tested but tests can often be run repeatedly against live data too. Also take advantage of time-based reporting: testing historical data, which is immutable, allows you to easily detect issues such as changing data structures.
- Run data quality tests against mock and live data. These tests can be plugged into developer laptops, CI/CD pipelines or live data accessed through specific data products or an orchestration layer. Typical data quality tests verify that a value should contain values between 0-60, alphanumeric values of a specific format, or that the start date of a project is at or before the end date. Test-driven design is another approach that can be used successfully in a data mesh.
- Include business-domain subject-matter experts when designing your tests
- Include data consumers when designing your tests. Data meshes should be driven by data consumers and it’s important to make sure your data products meet their needs
- Use automated testing frameworks that specialize in API testing
#3: Tight coupling between data products
The design influence of microservices on a data mesh is apparent in its flexible nature. A data mesh can expand and contract to match your data topology as it grows in some areas and shrinks in others. Different technologies like streaming can be used where needed and data products can scale up and down to meet demand.
As with microservices, tight coupling is the enemy of a highly functional data mesh. The “independently deployable” rule as applied to microservices also applies to data meshes: every data product on a mesh should be deployable at any time without making corresponding changes to other data products in the mesh. Adhering to this rule in a data mesh often would require some form of versioning scheme be applied to the data products.
#4: Failure to accurately version data products
Data products need to be versioned as data changes, and users of that data product (including maintainers of dashboards) must be notified about such changes – both breaking and non-breaking. Meanwhile, consumed data products need to be managed like resources in Helm charts or artifacts in Maven Artifactory.
#5: Sync vs async vs pre-assembled results
If a data mesh uses synchronous REST calls to package the output from multiple data products, chances are the performance will be acceptable. But if the data mesh is used for more in-depth analytics, combining a larger number of data products (such as the analysis typically done by a data lake), it’s easy to see how synchronous communication might become a performance issue.
So, what are the options? One solution is to use Command and Query Responsibility Segregation (CQRS) to pre-build and cache data results on a regular cadence. The cached results can then be combined into a more complex data structure when the data product is run unless you literally require up-to-the-moment results.
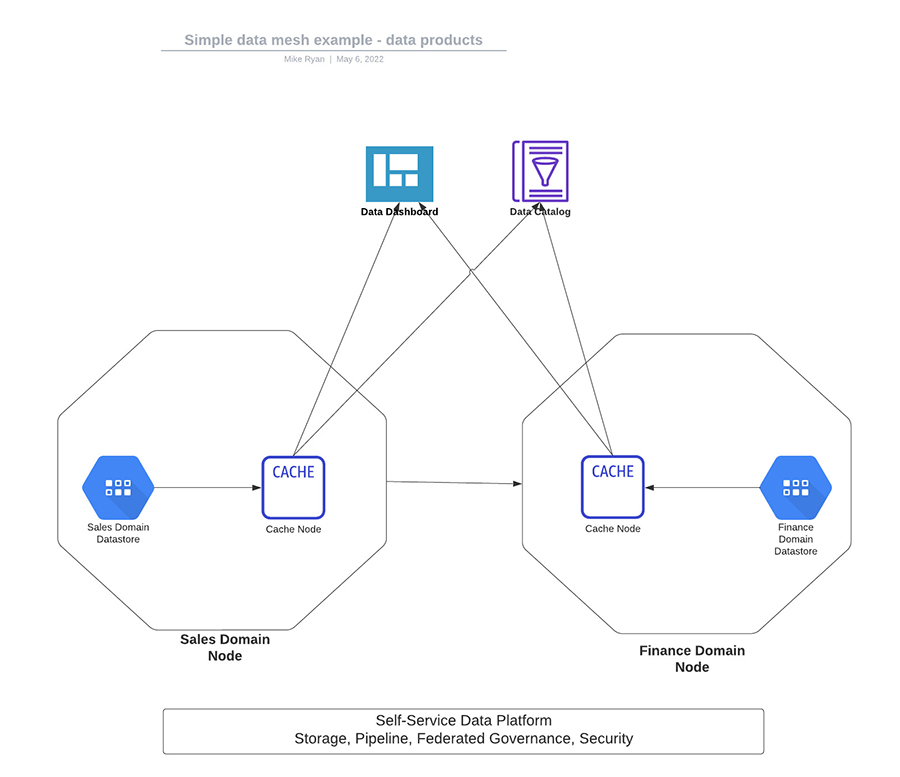
Another approach is to the operation into separate pieces that can be run asynchronously using an asynchronous Request-Reply pattern. Using this pattern implies:
- There are no ordering dependencies between the datasets (so if you concurrently build five datasets for example, the content of Dataset #2 cannot be dependent on the content of Dataset #1).
- Most likely, the caller will not receive an immediate response to their request. Instead, some sort of polling technique should be employed, returning successful results when all datasets are built and combined. If the dataset is very large, it may be stored somewhere and a link to the dataset provided to the user. This implies appropriate infrastructure and security are in place.
Not just technical challenges...
Embracing data mesh is no simple task. As every organization is unique, adopting data mesh requires a complete shift in the data management paradigm, forcing teams to think – and radically change – their data management strategy, processes, and ways of working. Our next blog addresses the operational challenges and how to address them.

